





In the realm of cloud computing and artificial intelligence (AI), Amazon Web Services (AWS) stands as a powerful enabler, offering a suite of services to deploy, manage, and scale AI models effortlessly. In this article, we delve into the seamless integration of Hugging Face models with AWS SageMaker, coupled with the activation of these models through Amazon API Gateway and Lambda functions.
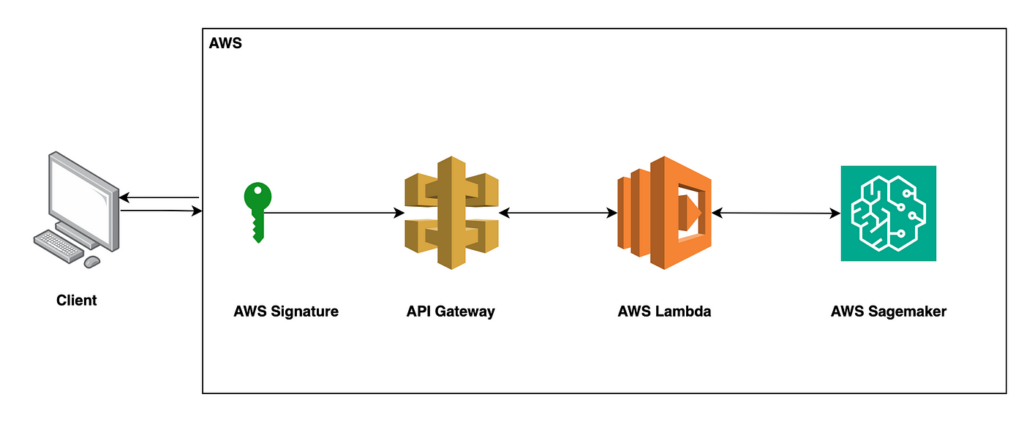
Understanding the AWS Trio: Lambda, SageMaker, and API Gateway
Before we embark on our journey, let’s briefly acquaint ourselves with the key players in our AWS saga:
- AWS Lambda: Lambda is a serverless computing service that enables you to run code without provisioning or managing servers. It responds to events triggered by other AWS services or HTTP requests using API Gateway, making it ideal for lightweight, event-driven tasks.
- Amazon SageMaker: SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. It offers a comprehensive set of tools for all stages of the ML lifecycle, from data preparation to model deployment.
- Amazon API Gateway: API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. It acts as a bridge between Lambda functions and external clients, allowing seamless integration and communication.
Deployment of Hugging Face Models in SageMaker
The journey begins with deploying our Hugging Face models in SageMaker. With SageMaker’s seamless integration with popular deep learning frameworks, such as PyTorch and TensorFlow, deploying Hugging Face models becomes a breeze. By leveraging SageMaker’s model hosting capabilities, we create an endpoint that can be invoked from Lambda functions.
a. Create a domain and establish a studio within it, granting access to Jupyter Lab for your work environment.
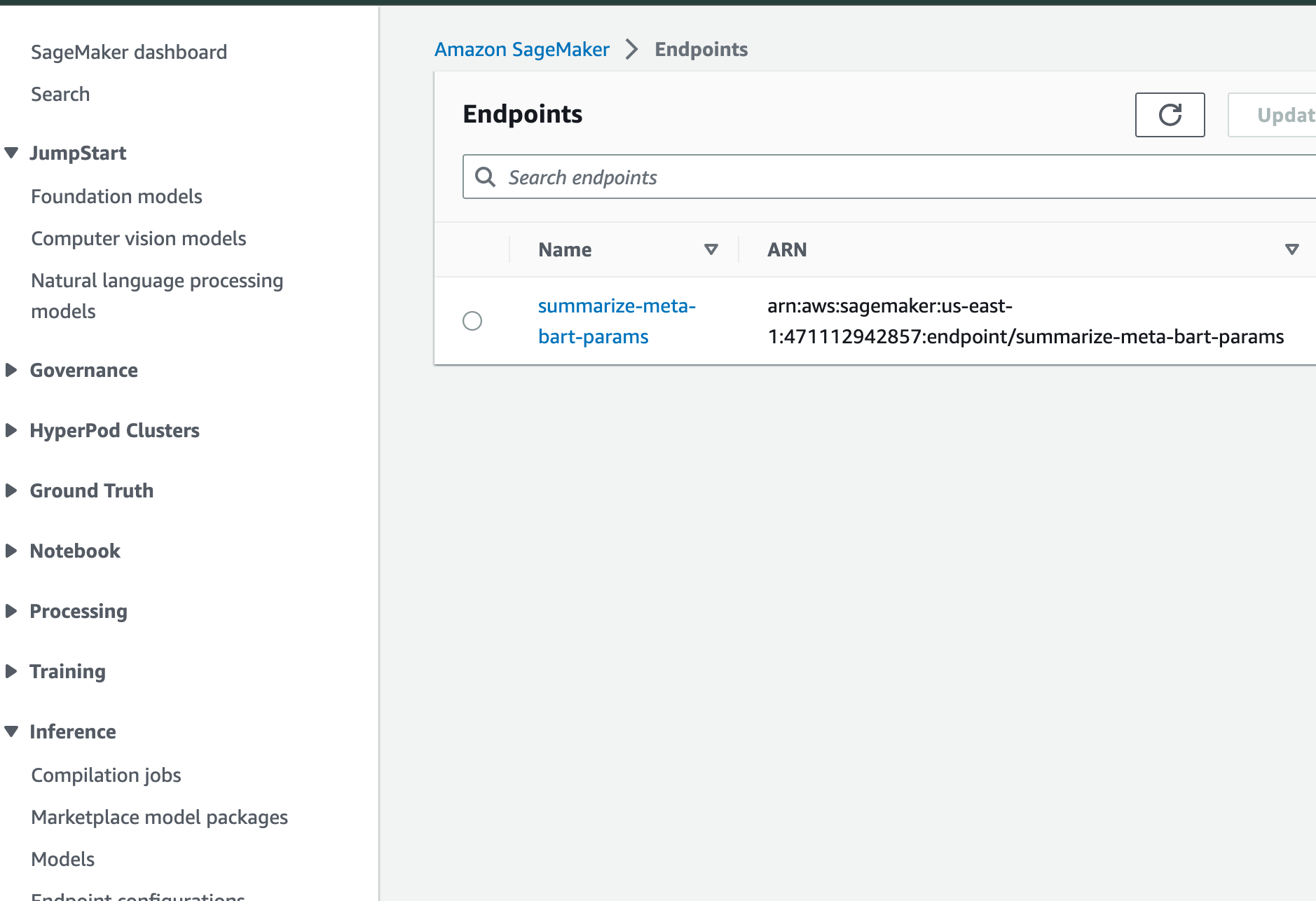
b. Develop your model in the notebook and save it, thereby generating both the model itself and an endpoint for consumption.

Creating a Lambda Function for Model Invocation
Next, we craft a Lambda function that serves as the conduit between our API Gateway and the SageMaker endpoint hosting our Hugging Face model. This Lambda function listens for incoming requests from API Gateway, triggers the execution of the Hugging Face model in SageMaker, and returns the results to the client.
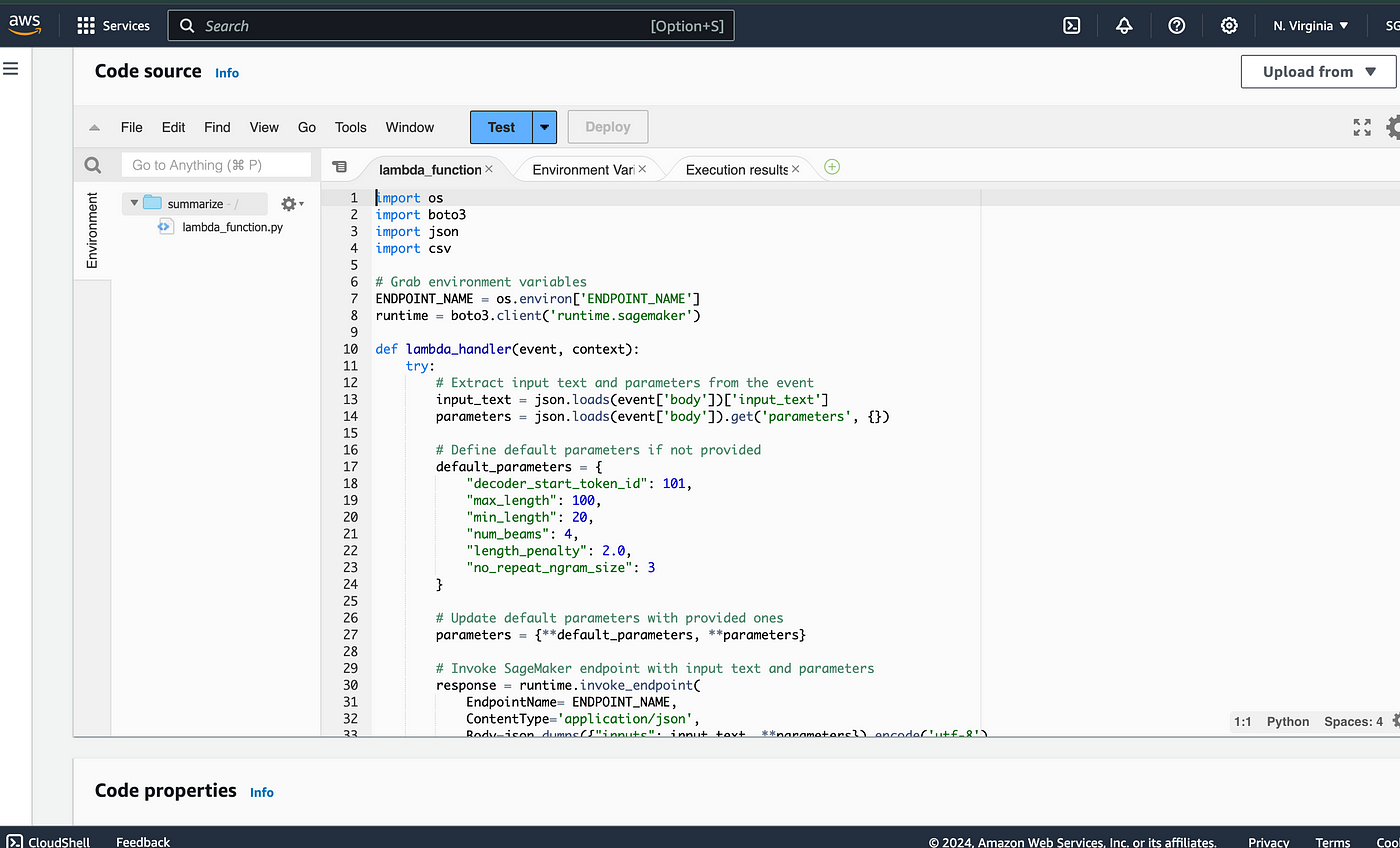
import os
import boto3
import json
import csv
# Grab environment variables
ENDPOINT_NAME = os.environ['ENDPOINT_NAME']
runtime = boto3.client('runtime.sagemaker')
def lambda_handler(event, context):
try:
# Extract input text and parameters from the event
input_text = json.loads(event['body'])['input_text']
parameters = json.loads(event['body']).get('parameters', {})
# Define default parameters if not provided
default_parameters = {
"decoder_start_token_id": 101,
"max_length": 100,
"min_length": 20,
"num_beams": 4,
"length_penalty": 2.0,
"no_repeat_ngram_size": 3
}
# Update default parameters with provided ones
parameters = {**default_parameters, **parameters}
# Invoke SageMaker endpoint with input text and parameters
response = runtime.invoke_endpoint(
EndpointName= ENDPOINT_NAME,
ContentType='application/json',
Body=json.dumps({"inputs": input_text, **parameters}).encode('utf-8')
)
# Parse response from SageMaker
result = json.loads(response['Body'].read().decode('utf-8'))
# Prepare response
response_dict = {
"statusCode": 200,
"body": json.dumps({"summary_text": result})
}
except Exception as e:
# Handle exceptions
response_dict = {
"statusCode": 500,
"body": json.dumps({"error": str(e)})
}
return response_dict
Configuring API Gateway for Secure Invocation
To ensure secure invocation of our API, we configure API Gateway to authenticate requests using IAM (Identity and Access Management) authentication. This prevents unauthorized access and ensures that only authenticated users can invoke our Lambda function and access our Hugging Face model.
Use Cloudwatch for Monitoring
After developing and deploying your model in the Jupyter Lab environment, it’s essential to monitor its performance and debug any issues that may arise during consumption. Utilizing CloudWatch, AWS’s comprehensive monitoring and logging service, allows you to track various metrics, such as endpoint latency, invocation counts, and error rates. By configuring CloudWatch to capture logs from your SageMaker endpoint, you gain valuable insights into the execution of your model, enabling you to identify and troubleshoot any potential issues effectively. With CloudWatch’s real-time monitoring capabilities and detailed logging features, you can proactively address performance bottlenecks, optimize resource utilization, and ensure the seamless operation of your AI application.
Conclusion
In conclusion, the seamless integration of Hugging Face models with AWS services like SageMaker, Lambda, and API Gateway empowers developers to harness the full potential of AI in their applications. By following the steps outlined in this article, you can deploy Hugging Face models with ease, activate them securely through API Gateway and Lambda functions, and unlock the transformative power of AI in your projects.
Read More Such Content Here: LINK