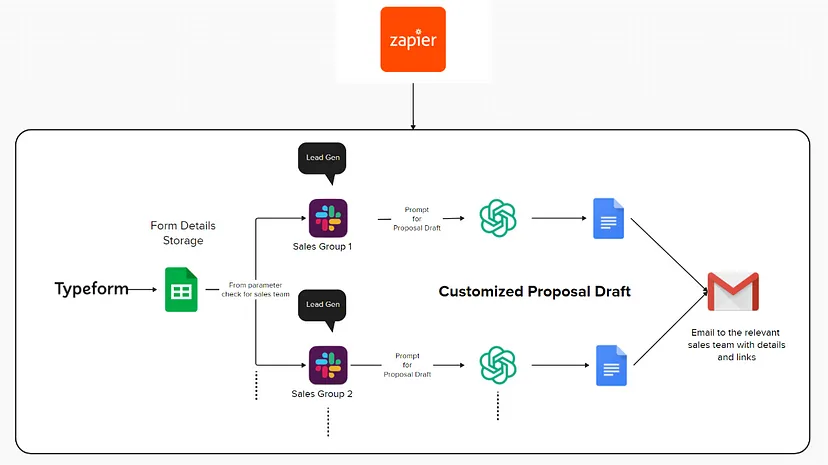





RAG, or Retrieval-Augmented Generation, is a hybrid approach in large language models (LLMs) that combines the strengths of both retrieval-based and generation-based models. While traditional LLMs, like GPT-3, are adept at generating human-like text, they sometimes need help retrieving specific, up-to-date, or domain-specific information. This is where RAG shines.

Why is RAG Important?
In LLM-based applications, generating accurate and contextually relevant information is crucial. Standard models, although powerful, may not have access to the latest information or specific details required for certain queries. RAG addresses this by incorporating a retrieval step, where relevant documents or information are fetched before generating the final output. This ensures that the response is both accurate and aligned with the user’s query.
Key Benefits of RAG:
- Improved Accuracy: By retrieving relevant documents before generation, RAG ensures that the model has access to specific, up-to-date information.
- Domain-Specific Responses: It allows the model to generate responses based on a curated set of documents, making it ideal for specialized domains.
- Efficiency: RAG models can reduce hallucinations (incorrect or fabricated outputs) by grounding responses in real, retrieved data.
Building RAG Models with OpenAI and LangChain
LangChain is a powerful framework designed to assist in building applications around LLMs, particularly those that require interactions between multiple models and systems. Here’s how you can leverage OpenAI and LangChain to build a RAG model.
1. Setting Up the Document Store
To begin, you need a collection of documents that your RAG model can retrieve from. These documents can be in various formats, such as markdown, PDFs, or even HTML pages.
Here’s a Python snippet that sets up a document store using LangChain’s DirectoryLoader and Chroma:
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
import openai
import os
import shutil
openai.api_key = os.getenv('OPENAI_API_KEY')
CHROMA_PATH = "chroma"
DATA_PATH = "data/markdown"
def generate_data_store():
loader = DirectoryLoader(DATA_PATH, glob="*.md")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(documents)
if os.path.exists(CHROMA_PATH):
shutil.rmtree(CHROMA_PATH)
db = Chroma.from_documents(
chunks,
OpenAIEmbeddings(model="text-embedding-ada-002"),
persist_directory=CHROMA_PATH
)
db.persist()
generate_data_store()
Here’s what this code does:
- Load Documents: Using the
DirectoryLoader, it loads all markdown files from the specified directory. - Split Text: The documents are split into smaller chunks using a
RecursiveCharacterTextSplitterto ensure that each chunk is manageable for the model. - Save to Chroma: The chunks are then stored in a Chroma vector store, with embeddings generated using OpenAI’s embedding model.
2. Querying the Document Store
Once the document store is set up, you can query it to retrieve relevant information and generate responses using OpenAI’s language models. Here’s how:
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate
import openai
openai.api_key = os.getenv('OPENAI_API_KEY')
CHROMA_PATH = "chroma"
PROMPT_TEMPLATE = """
Answer the question based only on the following context:
{context}
---
Answer the question based on the above context: {question}
"""
def generate_response(query_text):
embedding_function = OpenAIEmbeddings()
db = Chroma(persist_directory=CHROMA_PATH, embedding_function=embedding_function)
results = db.similarity_search_with_relevance_scores(query_text, k=3)
if not results or results[0][1] < 0.7:
return "Unable to find matching results."
context_text = "\n\n---\n\n".join([doc.page_content for doc, _ in results])
prompt_template = ChatPromptTemplate.from_template(PROMPT_TEMPLATE)
prompt = prompt_template.format(context=context_text, question=query_text)
model = ChatOpenAI()
response_text = model.predict(prompt)
sources = [doc.metadata.get("source", None) for doc, _ in results]
return f"Response: {response_text}\nSources: {sources}"
query = "What are the Four Basic Options Risk Profiles?"
print(generate_response(query))
This code works as follows:
- Query the Database: It uses Chroma to search for the most relevant document chunks related to the query.
- Generate Response: The retrieved context is fed into a prompt template and passed to OpenAI’s
ChatOpenAImodel to generate the final response. - Output: The model generates an answer grounded in the retrieved context, reducing hallucinations and improving accuracy.

Building RAG Models with OpenAI and LlamaIndex
LlamaIndex is a powerful framework that simplifies the process of building RAG models. It provides a flexible way to create and query indices of your documents, allowing you to retrieve relevant information efficiently and combine it with OpenAI’s models to generate accurate responses.
Here’s how you can build a RAG model using LlamaIndex and OpenAI:
1. Set Up the Document Index
First, you need to load your documents and create an index using LlamaIndex. This index will allow you to perform fast and efficient retrieval of relevant information.
from llama_index import SimpleDirectoryReader, GPTSimpleVectorIndex
import openai
import os
# Load your OpenAI API key
openai.api_key = os.getenv('OPENAI_API_KEY')
# Load documents from a directory
documents = SimpleDirectoryReader('data/markdown').load_data()
# Create an index of the documents
index = GPTSimpleVectorIndex(documents)
# Save the index for future use
index.save_to_disk('index.json')
This code does the following:
- Load Documents: The
SimpleDirectoryReaderloads all files in thedatadirectory. - Create Index: The
GPTSimpleVectorIndexcreates a vector-based index of the documents using embeddings. - Save Index: The index is saved to disk for future queries.
2. Query the Index and Generate Responses
Once the index is created, you can query it to retrieve relevant documents and use OpenAI to generate responses based on the retrieved context.
from llama_index import GPTSimpleVectorIndex
import openai
# Load the pre-built index
index = GPTSimpleVectorIndex.load_from_disk('index.json')
def generate_response(query_text):
# Query the index for relevant documents
response = index.query(query_text)
# Extract the context from the response
context_text = response.response
# Create the prompt with the retrieved context
prompt = f"Context:\n{context_text}\n\nQuestion: {query_text}\nAnswer:"
# Use OpenAI's model to generate a response
openai_response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=100
)
return openai_response.choices[0].text.strip()
# Example query
query = "What are the Four Basic Options Risk Profiles?"
print(generate_response(query))
This code works as follows:
- Query the Index: The
index.queryfunction retrieves the most relevant document chunks based on the query. - Generate Response: The retrieved context is combined with the query to create a prompt. This prompt is then passed to OpenAI’s
text-davinci-003model to generate a response.
3. Fine-tuning the Model for Specific Needs
You can further fine-tune the RAG model by adjusting the prompt, refining the document retrieval, or customizing the OpenAI model parameters to fit your specific application.
Conclusion
RAG models are revolutionizing LLM-based applications by merging the precision of retrieval with the creativity of generative AI. By integrating Chroma or LlamaIndex with OpenAI’s cutting-edge models, developers can craft systems that are not only highly accurate but also contextually aware and dynamically responsive to new information. Whether you opt for LangChain, LlamaIndex, or a hybrid approach, the true power lies in harnessing retrieval-augmented generation to build impactful, real-world solutions that stay relevant and effective in an ever-changing environment.
Discover more about our expertise and explore how we can assist with your AI and Data needs by visiting www.sgconsultingtech.com. Feel free to connect with me directly on LinkedIn for further discussion.